
redis
- Redis (Remote Dictionary Server) 개요
- 고성능의 키-값(key-value) 저장소로, 거대한 맵(Map) 데이터 저장소형태를 가지고 데이터를 메모리에 저장하여 빠른 읽기와 쓰기를 지원
- 주로 캐싱, 인증 관리, DB동시성 제어 등에서 다양한 목적으로 사용
- 레디스 주요 특징
- key-value로 구성된 단순화된 데이터 구조로 sql 쿼리 사용 불필요
- 빠른 성능
- 인메모리 NoSQL 데이터베이스로서 빠른 성능
- rdb는 기본적으로 disk에 저장이고 필요시에 메모리에 캐싱하는 것이므로, rdb보다 훨씬 빠른 성능
- redis의 메모리상의 데이터는 주기적으로 스냅샷 disk에 저장
- key-value는 구조적으로 해시 테이블을 사용함으로서 매우 빠른 속도로 데이터 검색 가능
- 인메모리 NoSQL 데이터베이스로서 빠른 성능
- Single Thread 구조로 동시성 이슈 발생X
- 윈도우 서버에서는 지원하지 않고, linux서버 및 macOS등에서 사용 가능
- 자료구조
- String, Lists, Sets, Sorted Sets, Hashes 등의 자료 구조를 지원
- redis에서 모든 key값은 문자열이고, value 또한 문자/숫자 구분 없이 모든 데이터를 문자열 형식으로 저장
- Strings
- 데이터를 String형태의 value로 저장
- 가장 일반적인 key - value 구조의 형태
- Lists
- 순서가 있는 문자열 목록
- deque(double-ended queue)와 유사한 구조
- Sets
- 중복을 허용하지 않는 문자열 집합
- Sorted Sets
- 점수가 할당된 문자열로 이루어진 집합, score를 기준으로 정렬된 순서로 관리
- Hashes
- Hash는 value값이 map자료구조
- redis 주요 스크립트
- redis 데이터베이스는 0~15까지로 16개로 구성
-
- select 데이터베이스숫자
- 최초 접속시 default 0번
-
- 주요 자료구조별 특징과 주요 명령어
- 모든 key값 조회
- keys *
- 키 삭제
- DEL key
- 전체 삭제는 FLUSHDB(현재 데이터베이스의 모든 key삭제)
- String관련
- 키에 값을 설정
- SET key value
- 키의 값을 가져옴
- GET key
- NX 문법
- key값이 존재하지 않는다면(if not exists) 값 setting
- set key value nx
- EX 문법
- “set key값 value값 nx ex 초단위시간” 형식으로 key유지(만료) 시간 세팅
- “EXPIRE key값 3600” 이런식으로 별도 부여도 가능
- TTL(Time To Live)이라 부르기도 함.
- “ttl key값” 명령어를 통해 남은 만료시간 확인 가능
- 활용
- 좋아요 기능 구현
- 재고 처리(동시성 이슈 해결)
- 캐싱처리(json형식의 데이터를 value값으로 많이 사용)
- 키에 값을 설정
- list
- deque 또는 double-ended queue 와 유사한 구조
- 데이터 추가
- LPUSH key value
- RPUSH key value
- 데이터 중간에 삽입 불가
- 데이터 추출 : LPOP key, RPOP key
- 데이터 개수 조회 : LLEN key
- 활용
- 웹사이트 최근방문, 최근 살펴본 상품 리스트 등
- SET
- set은 순서가 없고 중복이 없는 자료구조
- set(집합)에 멤버 추가
- SADD myset member
- set(집합)의 모든 멤버 반환
- SMEMBERS myset
- set의 멤버 개수 반환
- SCARD myset
- 특정 멤버 삭제
- SREM myset member1
- 활용
- 매일 방문자수 계산
- 좋아요 수 중복없이 집계
- zset(정렬된 집합)
- 정렬의 기준이 되는 score를 가지고 있는 set
- ZADD key score member
- score : 멤버를 정렬하는 데 사용되는 점수
- ZREM key member
- 특정키의 특정멤버 삭제
- ZRANK key member
- 특정멤버의 위치 정보 반환
- ZRANGE stock_prices 0 -1
- score기준 오름차순 조회
- ZREVRANGE stock_prices 0 -1
- score기준 내림차순 조회
- ZRANGE my_key 0 -1 WITHSCORES
- withscores가 없을때는 값만 오름/내림차순으로 반환. withscores가 있을때는 score까지 함께 반환
- 활용
- 주식, 코인 등의 실시간 시세저장 또는 게임 등의 사용자의 점수나 순위를 관리
- 최근 살펴본 상품(리스트 중복제거)
- hashes
- value값이 map형태인 자료구조
- 일반 문자열 저장과의 비교
- json형식의 객체 데이터를 일반문자열로 set하게 될경우, 특정 요소 수정/삭제시 전체 데이터를 변경
- hash는 map형식의 자료구조를 활용해 특정 데이터만 수정/삭제 용이
- 주요 메서드
- HSET
- HGET
- HGETALL
- HINCRBY
- 활용
- 빈번히 변경될 가능성이 있는 객체 형식의 데이터 캐싱
- hash는 특정 요소값만을 변경하기 용이
- json형식의 문자열의 경우 데이터를 일일이 parsing 후 재 setting해야 하는 비효율
- 빈번히 변경될 가능성이 있는 객체 형식의 데이터 캐싱
- 모든 key값 조회
1) redis 활용
일반 rdb를 쓸 경우 멀티쓰레드이기에 동시성 이슈가 발생할 수 있다.
redis는 단일스레드이며 성능또한 좋기에 동시성 이슈를 아예 배제하고 사용할 수 있기에 활용도가 높다
1. 좋아요 기능

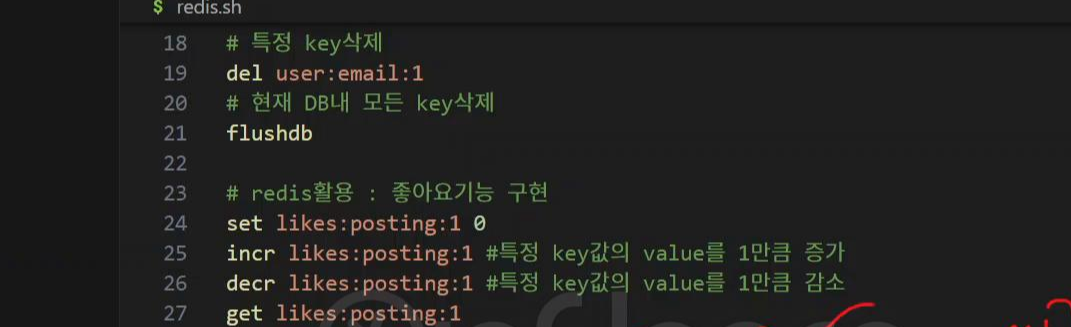
key 등록
set likes:posting:1 0
key값 likes:posting:1
value값 0
incr likes:posting:1
"likes:posting:1 값을 증가"
decr likes:posting:1
"likes:posting:1 값을 감소"
2. 재고관리 기능
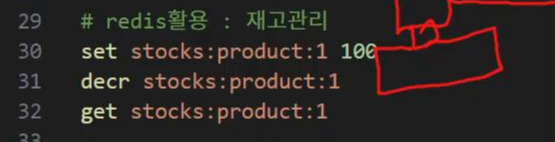
3. 캐싱(임시저장) 기능
임시저장된 사이트를 예를 들어 rdb에 저장한다고 하면, 조회 속도가 엄청 느림
redis는 storage에 정기적으로 저장하지만, rdb보단 불안정하다.
그래서 모든 데이터를 redis에 저장할 순 없음
인기글의 경우(빈번하게 조회되는 경우)
최초 조회 시 return 전 redis에 저장 후 응답하고, 다음 사용자가 조회 요청 시 redis에 임시 저장된 것이 있는 지
확인 후 응답하면 응답 속도가 훨씬 높다.
but 만료기간을 저장해주는 것이 적절하게 캐싱을 활용할 수 있다.

posting된 게시글을 json 형태로 저장
2) redis의 list

일반적으로 deque와 유사함

lpush와 rpush 후 hongildongs에 저장된 list 확인
"lrange key start end" 로 list에 저장된 key에 대한 시작 지점과 끝 지점을 선택해 확인할 수 있다.

rpop 후에 확인
오른 쪽에 담겨있는 hong3가 빠져나감

list 조회




llen는 데이터의 갯수 조회
expire는 이미 만들어진 key 에다가 ttl 적용 가능
ttl로 ttl 시간 조회 가능
주의

만료시간이 지나면 키 자체가 다 사라짐
list 활용
최근 방문한 페이지, 최근 조회한 상품목록
예를 들어 최근 방문한 페이지를 2개를 return 하고 싶을 때 list를 사용하게 되면
"lrange key -2 -1"로 반환해주면 될 듯
예시)
최근 사용한 페이지 5개를 활용
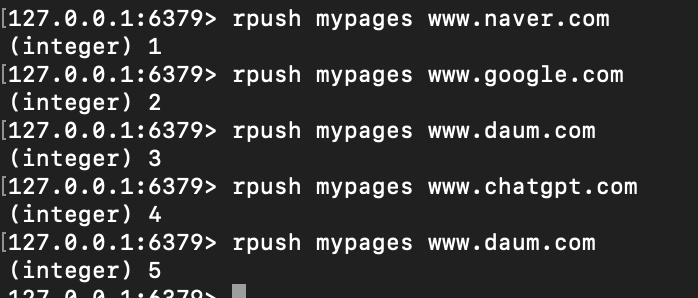
확인 결과

문제점
페이지의 경우 상관없지만, 최근 조회된 상품의 경우 중복도 없고, 중복일 시 순서가 유지되고 싶다.
기본적으로 list는 중복을 허용하기에 위에 daum.com 의 경우 중복허용
이럴 땐 zset을 활용!
3) redis의 set

set에 추가 "sadd 키 value"

set의 값을 확인하고 싶을 땐
"smembers 키"
결과로 중복이 허용 안된 것을 볼 수 있다.


요소의 크기를 확인하고 싶을 때 (cardinality)
"scard 키"
set 요소를 삭제하고 싶을 때 (remove)
"srem 키 값"
set 요소에 있는 지 확인하고 싶을 때
"sismember 키 값"
return 값은 0 or 1
1. set의 활용
중복이 되지 않는 방문자 수, 좋아요 등

좋아요 시 한 사람이 중복해서 누를 수 없게 하기 위해 값에다 member에 대한 정보를 넣어주면
중복으로 좋아요를 할 수 없게끔 활용 가능
redis의 zset
중복이 없는 정렬된 집합

1. 요소 추가
zset에 추가하고 싶을 때
"zadd 키 스코어 값"
score는 정렬을 할 기준 값

기본적으로 score를 기준으로오름차순으로 정렬함
"zrange 키 시작 종료"
오름차순 정렬
"zrevrange 키 시작 종료" (reverse)
내림차순 정렬
2. 요소 삭제

"zrem 키 값"
요소를 삭제하는 것이기에 score를 직접 지정할 필요는 없다.
3. 특정 멤버 순서 출력

"zrank 키 값"
특정 키에 대한 값이 몇 번째인지 확인할 수 있다.
특징적으로 오름차순으로 기준
4. zset 활용
list를 활용 시 최근 방문한 페이지, 최근 조회한 상품목록을 조회 했을 때 중복된 페이지를
제거할 수 없는 문제점이 있었다.
이 것을 zset으로 해결!
(set을 활용하기 힘든 게 순서가 필요하다.)
score를 조회한 시간을 기준으로 주면 정렬이 가능
ex) 최근 조회한 상품목록

최근 본 상품에 스코어는 시간기준으로 파인애플, 바나나, 오렌지, 사과를 넣어줌
중복을 넣고 확인했더니 먼저 넣은 152230 사과는 사라지고 뒤에 넣은 152330 사과로 덮어쓰기!
(zset : 시간이 업데이트되고, 덮어쓰기 기억)

최근 목록으로 뽑아보니, 시간 순으로 나중에 들어간 것이 확인 가능(apple도 중복제거 됨을 확인)
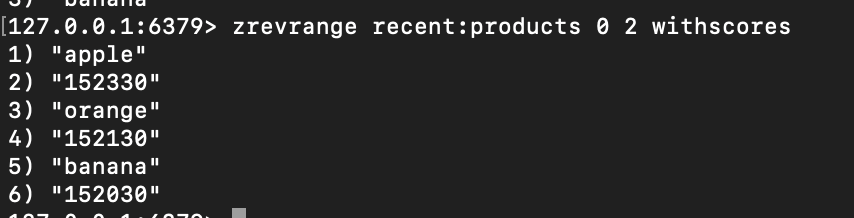
range로 확인할 때 마지막에 "withscores" 로 스코어까지 확인 가능!
또 다른 예제로 주식의 실시간 시세 및 게이머 별 점수나 순위를 관리에도 유용!
redis의 hashes
map형태의 자료구조이고,
value 값이 map 형태로 되어 있는 구조 키{ ..} : 값{key : value, key : value ...}
(자바에서 value 값에 map을 넣는 구조)
"hset 키 {키 값} {키 값} .."

1. hset 조회
"hget 키 키"

member:info:1에 해당하는 값의 키들은 name, email, age가 있고,
name을 조회 했을 때, "hong"
email을 조회 했을 때, "hong@naver.com"
age를 조회 했을 때, "30"
모든 값을 조회 하고 싶다면
"hgetall member:info:1"
2. hset 수정

특정 값에 대해 수정 가능
hset으로 기존처럼 덮어쓰고, 다시 조회했을 때 name이 바뀐 것을 확인
3. hset의 값을 증가/감소
age에 3을 증가 or 감소시키고 싶다면?
"hincrby 키 키 증가요소"
(양수나 음수에 따라 증가/감소)
4. hset 활용
list나 set으로 값을 그냥 json형태로 넣게 된다면 값 요소 하나를 수정할 때 전체를 다 파싱해서 통째로 수정해야하지만,
값을 map 형태로 넣게 된다면 위처럼 하나의 값만 쉽게 바꿀 수 있다.
그래서 요소의 값들이 빈번하게 변경된다면? hset 활용 객체로 활용함
