https://school.programmers.co.kr/learn/courses/30/lessons/42747
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
timSort,mergeSort,DualPivotQuicksort ( 목차를 좀 더 간략하게 보여야겠다)
1. 문제 및 접근방법
문제를 잘 읽어야 한다.. h 수를 찾자
논문의 배열이 들어오고 h번보다 큰거나 같은 수가 h개 있어야하고, 나머지는 h보다 작거나 같은 수라면 그 수가 답이다
1000개의 논문이 들어오고 논문의 숫자는 0~10,000이다
즉 h는 중간 값 찾는 거 같은데 ? ( 이렇게 생각했는데 틀렸다 )
계속 배열이 들어온다면 heap을 통해 효율적으로 정렬할 수 있다는 걸 배웠다
2. 풀이법
private int solution(int[] citations) {
int answer = 0;
int size = citations.length;
sorted = new int[size];
mergeSort(citations, 0, size - 1);
for (int i = 0; i < size; i++) {
int h = size - i;
if (citations[i] >= h) {
answer = h;
break;
}
}
return answer;
}
전체 풀이법
2-1 merge Sort
private static void mergeSort(int[] arr, int left, int right) {
if(left == right) return; // 둘다 같다는 건 나눈 리스트들이 1개의 요소를 가진 기저조건
int mid = (left + right) / 2; // mid 는 중간 값으로 두개 나누기 위해
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
private static void merge(int[] arr, int left, int mid, int right) {
// 정렬된 양쪽 배열을 하나의 배열로 합치기 위한 메서드
int l = left; //
int r = mid + 1;
int idx = left; // 배열에 채워넣을 현재 인덱스
while (l <= mid && r <= right) { // 하나씩 돌면서
if (arr[l] <= arr[r]) { // 두개의 배열의 왼 배열이 실제 값이 작거나 같으면 그 수 먼저
sorted[idx] = arr[l]; // 작은 수를 실제로 넣어주고
idx++; // 인덱스 올려주고,
l++; // 완쪽배열의 인덱스를 올려줌
}
else {
sorted[idx] = arr[r];
idx++;
r++;
}
}
if (l > mid) { // 다 돌았는데 mid보다 l이 크다는 건 오른쪽 배열의 수만 남고 왼쪽 배열만 다 채워졌다는 뜻
while (r <= right) {
sorted[idx] = arr[r];
idx++;
r++;
}
}
else {
while (l <= mid) { // 다 돌았는데 mid r
sorted[idx] = arr[l];
idx++;
l++;
}
}
for (int i = left; i <= right; i++) { // 기존 배열에 다시 정렬된 배열을 넣어주기 !
arr[i] = sorted[i];
}
}
정렬은 merge sort를 Top Down 형식으로 재귀를 호출해
정복 & 분할로 구현해뒀다.
자세한 건 밑에 다시 설명하겠다.
2-2 h 수 찾기

완료된 정렬 후
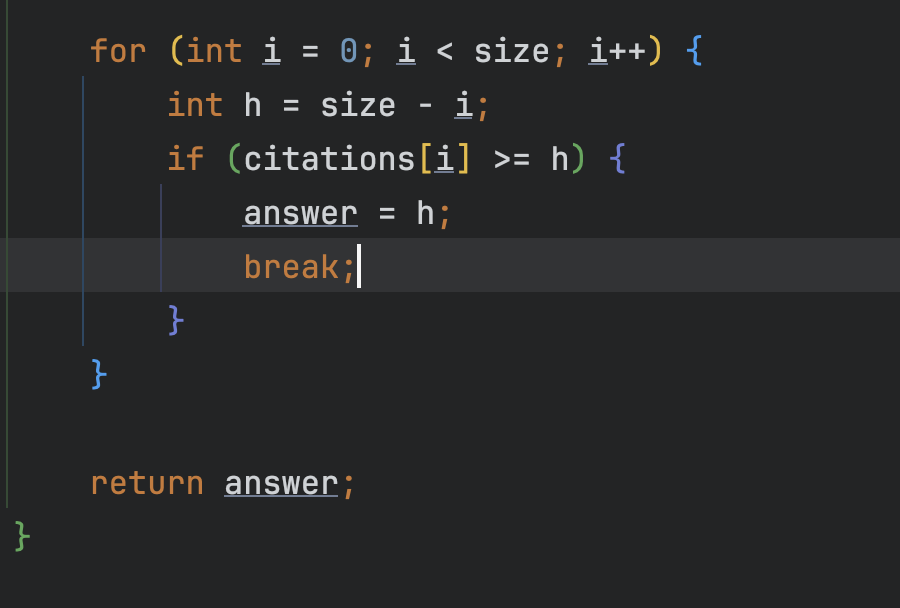
for문을 돌면서 예시를 보자

3. sort
사실 Arrays.sort() 나 Collections.sort()를 쓰면 편하지만 merge sort를 가끔씩 구현해줘야 까먹지 않는다.
그리고 Arrays.sort()와 Collections.sort()는 다른 알고리즘으로 정렬한다.
3-1 Arrays.sort()
Arrays.sort()는 DualPivotQuicksort를 구현했으며

일반적인 Quicksort의 경우 1개의 Pivot으로 정렬을 수행하지만 DualPivotQuicksort는 피벗을 2개 사용해서 정렬을 수행한다.
Quicksort는 최악의 경우 O(N^2), 평균적으로 O(NlogN)의 시간 복잡도를 가진다..
DualPivotQuicksort은 pivot이 두개라 랜덤 데이터에 대해 일반적인 Quicksort보다 나은 시간 복잡도를 보장하지만, 대부분의 시간 복
잡도 O(NlogN)는 동일하다. (
즉 평균 O(NlogN)의 시간복잡도를 가지며 (모두 정렬되어 있을 경우 )최악의 경우 O(n^2)이 될 수 있다.
3-2 Collections.sort()

Collections.sort()의 경우엔 list.sort()로 구현되어 있어 찾아가보자

다시 Array.sort()에서 구현하고 있어 깊게 들어가보면

TimSort로 구현하고 있다.
(예전에 deprecated라고 적힌 걸 본 것 같은데.. 자세한 건 모르겠다)
TimSort 란 ?
Merge Sort와 Insert Sort를 결합해 만든 하이브리드 정렬 알고리즘이다
최선은 O(N)최악의 경우에도 O(NlogN)의 시간 복잡도를 가진다.
참조 지역성이라는 어려운 용어를 만나자 힘들어졌네..
어려우니 자세한 설명은 밑에.. 주석 처리해두겠다


4. 마무리
문제가 어렵기 보다, 글을 이해하는데 더 오래 걸렸다. 문해력을 더 길러야할 거 같고,
정렬을 그냥 아무거나 썼는데 상황에 맞게 TimSort나 DualPivotQuicksort를 이해해서 쓰면 더 효율적이라는 생각이 들었다.
(사실 length에서 i를 빼줘야 하는데 1을 계속 빼서.. 계속 틀렸었다 멍총이)
'알고리즘' 카테고리의 다른 글
| 99클럽 코테 스터디 9일차 TIL 카펫 (0) | 2024.05.28 |
|---|---|
| FloodFill 알고리즘 (0) | 2024.05.28 |
| 99클럽 코테 스터디 7일차 TIL 가장 큰 수 (0) | 2024.05.26 |
| 99클럽 코테 스터디 5일차 TIL 더 맵게 (0) | 2024.05.24 |
| 99클럽 코테 스터디 4일차 TIL 올바른 괄호 feat(queue.add vs offer) (0) | 2024.05.23 |


